Spis treści
Wstęp
Bazy danych to struktury działające zazwyczaj w oderwaniu od interfejsu się z nimi komunikującego. Tak więc zwane są systemami bazodanowymi. Jednym ze standardów systemów bazodanowych jest rodzina oparta na SQL (Structured Query Language). Zanim usankcjonowała się hegemonia relacyjnego SQL to takimi systemami bazodanowymi był np. Clipper, obecnie pojawiają się również coraz silniejsze głosy propagujące systemy bazodanowe noSQL, czyli nierelacyjne bazy danych głośno nazywane next generation database systems, czy aby na pewno – prześledźmy poniżej.
Bazy danych NoSQL (ang. non SQL, non relational, Not Only SQL) – bazy danych, w których można przechowywać, organizować i wyszukiwać dane w inny sposób niż w tabelach relacyjnych znanych z tradycyjnych RDBMS.
NoSQL jest przydatny w przypadku danych o dużym wolumenie, które będzie można stosunkowo łatwo skalować horyzontalnie – w klastrach i na wielu serwerach – mowa między innymi o Big Data.
Big Data charakteryzuje się dużymi zbiorami danych, ciągłym przyrostem nowych i koniecznością ich wydajnego przetwarzania. Widać to w przypadku wyszukiwarek internetowych, sieci społecznościowych, innych skalowalnych aplikacji internetowych. Wyzwaniem dla Big Data jest przechowywanie, zapisywanie, analiza i transfer tych danych. NoSQL w rozwiązaniu tych problemów mają rzekomo przewagę nad rozwiązaniami SQL, ale dlaczego?
NoSQL łatwiej skalować horyzontalnie. Możliwość łatwego skalowania w poziomie jest wpisana w ideę NoSQL. Zgodnie z teorią CAP Erica Brewera, każda baza danych może mieć co najwyżej dwie cechy z poniższej listy:
- Spójność (ang. Consistency),
- Dostępność (ang. Availibility),
- Tolerancja partycjonowania (ang. Partition Tolerance).
W bazach NoSQL po prostu celowo rezygnuje się ze spójności na rzecz większej wydajności i tolerancji na partycje wprowadzając często różnego rodzaju redundancje (czyli dane nadmiarowe). Na czym polega ta rezygnacja? W bazach NoSQL zazwyczaj nie mamy wsparcia dla transakcji czyli nie spełniają one zasady ACID. Spójność po prostu nie jest w nich kluczowa.
Rodzaje baz danych NoSQL
NoSQL to szerokie pojęcie odnoszące się nie tylko do wybranej technologii. Poniżej wybrane rodzaje baz danych MySQL i przykładowe technologie:
- bazy danych dokumentów – MongoDB, CouchDB,
- kolumnowe bazy danych – Apache Cassandra,
- bazy danych typu klucz-wartość – Redis, Couchbase Server, DynamoDB,
- systemy pamięci podręcznej – Redis, Memcached,
- grafowe bazy danych – Neo4J, ArangoDB, FaunaDB, OrientDB.
Pełną listę można znaleźć na stronie http://nosql-database.org/.
Zalety baz danych NoSQL
Przewaga NoSQL nad SQL polega na tym, że:
- są bardziej przystosowane i wydajniejsze przy przetwarzaniu Big Data,
- modele danych – brak predefiniowanych schema (czyli schematów tabel, typów danych itp.) powoduje ich większą elastyczność,
- potrafią przetwarzać dane niestrukturalne,
- tańsze i prostsze w utrzymaniu (szczególnie w przypadku prostych baz klucz-wartość) nie wymagają skomplikowanych RDBMS,
- z natury skalowalne (łatwe skalowanie horyzontalne).
Wady baz danych NoSQL
- dla danych, w których występują relacje zalecane są nadal standardowe RDBMS,
- normalizacja w bazach relacyjnych pozwala na uniknięciu redundancji,
- relacyjne bazy danych rokują większą integralności i spójność danych,
- SQL jest szeroko znany,
- brak mechanizmów transakcyjnych – może nie spełniać zasady ACID (ang. Atomicity, Consistensy, Isolation, Durability)
Zastosowanie baz danych NoSQL
Praktycznie każda większa aplikacja webowa prędzej czy później będzie zmuszona wykorzystać bazy NoSQL choćby w celu utrzymywania pamięci podręcznej. Najpopularniejsze rozwiązania tego typu to przykładowo Redis i Memcached. Rozwiązania te warto wdrożyć nawet w małych aplikacjach i wykorzystać je w ramach pamięci podręcznej przechowywanej w pamięci RAM. Radykalnie skracając czas dostępu do danych przechowywanych w bazie MySQL zmniejszamy opóźnienie TTFB1Time to first byte (TTFB) jest wartością podawaną w mikrosekundach mierzoną od momentu wysłania zapytania, do chwili otrzymania przez użytkownika pierwszego bajtu danych wysłanych przez serwer. Parametr ten jest niestety jednym z popularniejszych sposobów mierzenia prędkości ładowania się strony., które jest kluczowe w przypadku prędkości działania i responsywności interakcji w serwisach WWW.
Serwis Facebook korzysta z Memcached. Instagram, Netflix i Apple wykorzystują architekturę Cassandra. Twitter, GitHub, Weibo, Pinterest, Snapchat, Craigslist, Digg, StackOverflow, Flickr wykorzystują Redis.
Współdziałanie SQL i NoSQL
Błędne jest patrzenie na technologie baz NoSQL jako alternatywę lub „konkurencję” dla standardowych baz SQL. Technologie te świetnie się uzupełniają i od lat są stosowane równolegle. Bazy danych NoSQL typu klucz-wartość wykorzystuje się jako warstwę pamięci podręcznej dla relacyjnych baz SQL. Przykładem może tutaj być Redis i Memcached, które wykorzystując możliwość łatwego skalowania horyzontalnego i wysokiej wydajności wspierają przetwarzanie danych w różnego rodzaju aplikacjach wymagających wysokiej dostępności i przetwarzania w czasie rzeczywistym.
Relacyjne Bazy Danych – SQL
W naszych zajęciach oprzemy się na zagadnieniach relacyjnie powiązanych z systemami bazodanowymi opartymi na SQL. Tych też jest przynajmniej kilka, są to m.in. MySQL lub inny klon MariaDB, jest to MS SQL oraz podstawa w naszych zajęciach to SQL oparty na produkcie firmy Oracle.
Aby jednak móc się tą tematyką zająć wpierw trzeba zapoznać się z zapisem relacji. Tutaj pomoże model Barkera.
Notacja Barkera
W skrócie temat ujmując można mówić o encji zawierającej atrybuty opisane trzema charakterystycznymi cechami, które są do wyboru:
- unikalne (#) – czyli takie, które w skali tabeli zawierającej rekordy są niepowtarzalne i tylko jeden rekord może zawierać określoną wartość
- Not Null (*) – czyli takie, które MUSZĄ się znaleźć w rekordzie (są wymagane)
- Opcjonalne (o) – czyli takie, które są danymi dodatkowymi i są uzupełniane w miarę potrzeby.
Notacja Barkera wymaga także, dla czytelności i rozumienia, aby tablice (Encje) oznaczone były nazwami pisanymi dużymi literami, a nazwy atrybuty były zrozumiałe co do tego co opisują i pisane z pierwszej dużej litery.
Relacje
Relacje pomiędzy encjami mogą być różnego typu:
- 1 do 1
- 1 do wielu (wiele do 1)
- wiele do wielu
Każda relacja może być także obowiązkowa (mandatory) – czyli taka, która określa, że instancja relacji MUSI być powiązana z inną instancją – obrazuje się je linią ciągłą.
Relacja może być też opcjonalną – czyli taką, która określa, że instancja MOŻE być powiązana z inną instancją – obrazuje się je linią przerywaną.
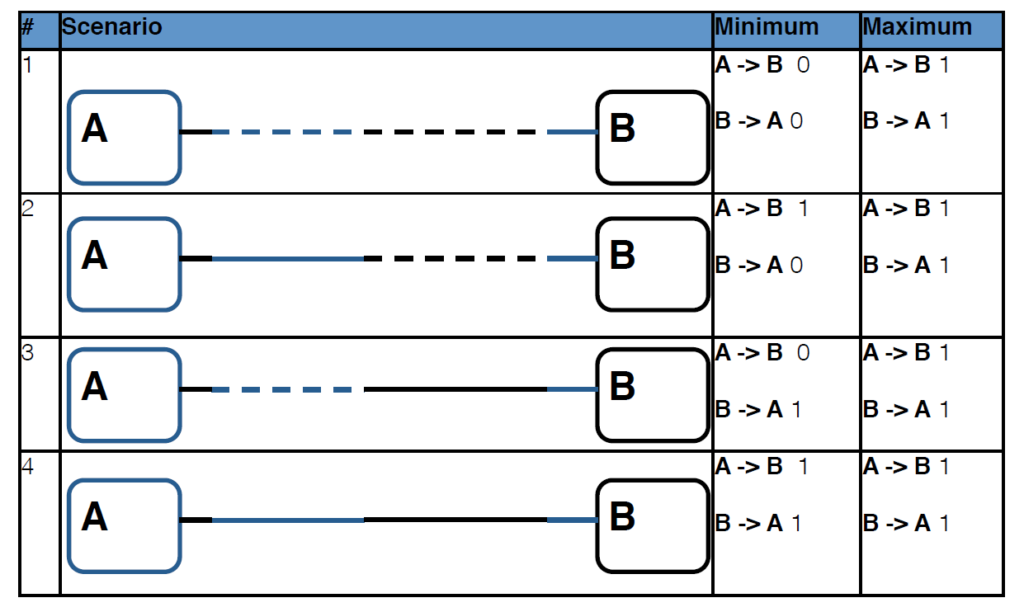
Relacja 1 do 1
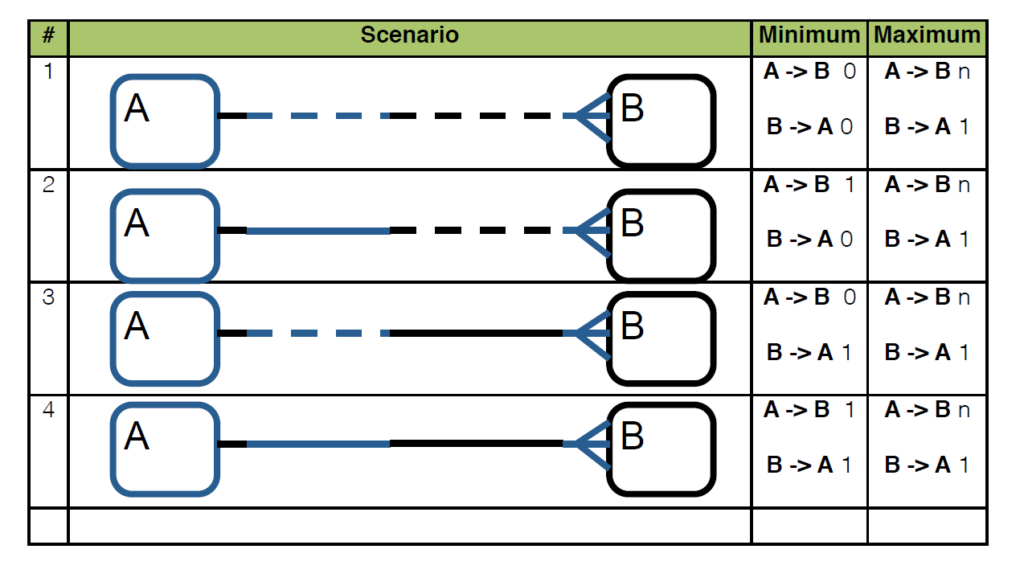
Relacja 1 do wielu
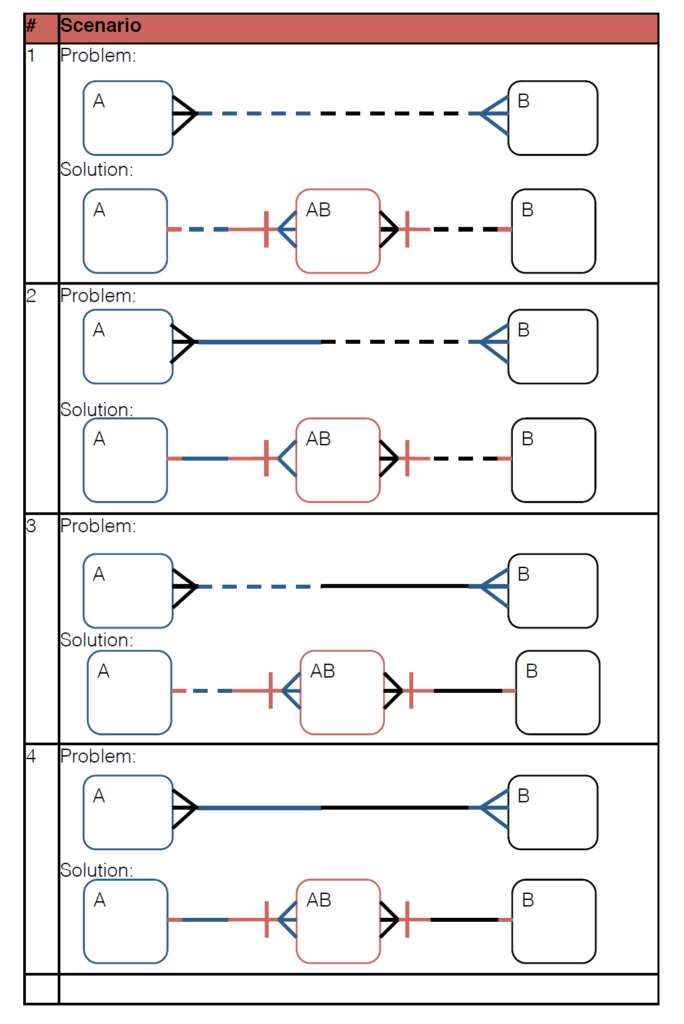
Relacja wiele do wielu
Nie jest to pożądana relacja i z zasady należy dokonać jej dekompozycji na relacje ściślejsze.
Data Modeler
Data Modeler jest narzędziem firmy Oracle umożliwiającym graficzne przedstawienie struktury bazy danych w postaci logicznej i/lub relacyjnej. Za pomocą tego narzędzia możemy stworzyć diagram ERD czyli Entity-Relationship Diagram przedstawiający powiązania pomiędzy encjami, oraz opisujący same encje. Finalnie możemy z tak opisanej bazy danych wygenerować skrypt do uruchomienia w ramach rzeczywistej bazy danych w celu stworzenia analogicznej do zaprojektowanej struktury.
Zadania
Zastanów się, zaplanuj ERD i wykonaj w Data Modelerze dla następujących zagadnień:
- Pilot może pilotować wiele samolotów, ale samolot może być w danej chwili pilotowany przez jednego pilota. Tenże samolot należy do jednej linii lotniczej, ale linia może mieć wiele samolotów.
- Drzewo rośnie w jednym sadzie, ale w sadzie może rosnąć wiele drzew.
- Sprzedawca na straganie sprzedaje różne owoce, ale jeden stragan należy do jednego sprzedawcy.
- Gracz może należeć do drużyny, ale drużyna może mieć wielu graczy; może ta drużyna jako jedna z wielu brać udział w rozgrywkach ligi i wygrać je; ta liga może być wygrana tylko przez jedną drużynę; liga jest organizowana przez konfederację, ale konfederacja może organizować wiele lig.