Spis treści
Czym jest relacyjna baza danych?
Relacyjna baza danych to rodzaj bazy danych, który pozwala przechowywać powiązane ze sobą elementy danych i zapewnia do nich dostęp. Relacyjne bazy danych są oparte na modelu relacyjnym — jest to prosty i intuicyjny sposób przedstawiania danych w tabelach. W relacyjnej bazie danych każdy wiersz tabeli jest rekordem z unikatowym identyfikatorem nazywanym kluczem. Kolumny tabeli zawierają atrybuty danych, a każdy rekord zawiera zwykle wartość dla każdego atrybutu, co ułatwia ustalenie relacji między poszczególnymi elementami rekordu.
Przykład relacyjnej bazy danych
Oto prosty przykład dwóch tabel, które mała firma może wykorzystać do przetwarzania zamówień na swoje produkty. Pierwsza tabela służy do przechowywania informacji na temat klientów. Jej każdy rekord zawiera nazwę, adres, informacje wysyłkowe i rozliczeniowe, numer telefonu oraz inne informacje kontaktowe klienta. Każdy fragment informacji (każdy atrybut) znajduje się w oddzielnej kolumnie, a baza danych przypisuje każdemu wierszowi unikatowy identyfikator (klucz). W drugiej tabeli — służącej do przechowywania zamówień klientów — każdy rekord zawiera identyfikator klienta, który złożył zamówienie, zamówiony produkt, ilość, wybrany rozmiar i kolor itd., ale nie zawiera nazwy ani danych kontaktowych klienta.
Te dwie tabele mają jedną wspólną cechę: kolumnę identyfikatora (klucza). Dzięki tej wspólnej kolumnie relacyjna baza danych może utworzyć relację między dwiema omawianymi tabelami. W chwili gdy aplikacja przetwarzająca zamówienia firmy przesyła zamówienie do bazy danych, baza danych może przejść do tabeli zamówień klienta, pobrać poprawne informacje o zamówieniu na produkt i użyć identyfikatora klienta z tej tabeli, aby wyszukać informacje rozliczeniowe i wysyłkowe klienta w tabeli informacji o kliencie. Magazyn może następnie pobrać właściwy produkt, klient może otrzymać zamówienie w terminie, a firma może otrzymać zapłatę.
Jak są zorganizowane relacyjne bazy danych
Model relacyjny oznacza, że logiczne struktury danych — tabele danych, widoki i indeksy — są oddzielone od fizycznych struktur pamięci. Dzięki temu administratorzy baz danych mogą zarządzać fizycznym przechowywaniem danych bez wpływu na dostęp do tych danych jako struktury logicznej. Na przykład zmiana nazwy pliku bazy danych nie powoduje zmiany nazw przechowywanych w nim tabel.
Rozróżnienie między strukturą logiczną a fizyczną dotyczy również operacji na bazach danych, które są wyraźnie zdefiniowanymi działaniami umożliwiającymi aplikacjom manipulowanie danymi i strukturami bazy danych. Operacje logiczne umożliwiają aplikacji określenie potrzebnej zawartości, a operacje fizyczne ustalają, w jaki sposób należy uzyskać dostęp do danych, a następnie wykonują to zadanie.
Aby zapewnić zawsze maksymalną dokładność i dostępność danych, relacyjne bazy danych przestrzegają określonych reguł integralności. Reguła integralności może na przykład określać, że w tabeli nie są dozwolone duplikaty wierszy, eliminując w ten sposób możliwość wprowadzenia do bazy danych błędnych informacji.
Model relacyjny
We wczesnych latach rozwoju baz danych każda aplikacja zapisywała dane w swojej własnej unikatowej strukturze. Chcąc tworzyć aplikacje korzystające z tych danych, programiści musieli dobrze znać konkretną strukturę danych, aby znaleźć potrzebne dane. Te struktury danych były nieefektywne i trudne do utrzymania. Trudno je też było zoptymalizować, aby zapewnić wysoką wydajność aplikacji. Relacyjny model bazy danych zaprojektowano w celu rozwiązania problemu istnienia wielu arbitralnych struktur danych.
Model relacyjny zapewnił standardowy sposób reprezentowania i wysyłania zapytań dotyczących danych, z którego można było korzystać w każdej aplikacji. Od samego początku programiści uznali, że główną siłą relacyjnego modelu bazy danych było wykorzystywanie tabel, które oferowały intuicyjny, wydajny i elastyczny sposób przechowywania ustrukturyzowanych informacji oraz uzyskiwania do nich dostępu.
Z czasem ujawniła się jeszcze jedna zaleta modelu relacyjnego. Programiści mogli bowiem korzystać z języka SQL (structured query language, strukturalny język zapytań) przeznaczonego do zadawania pytań i wyszukiwania danych w bazie danych. Przez wiele lat SQL był powszechnie używany jako język do formułowania zapytań do baz danych. Oparty na algebrze relacyjnej język SQL to wewnętrznie spójny język matematyczny, zapewniający wyższą wydajność wszystkich zapytań do baz danych. Dla porównania, inne podejścia wymagają definiowania pojedynczych zapytań.
Zalety relacyjnych baz danych
Prosty, ale silny model relacyjny jest używany przez różnego rodzaju i różnej wielkości przedsiębiorstwa do zaspokajania szerokiej gamy potrzeb informacyjnych. Relacyjne bazy danych służą do śledzenia zapasów, przetwarzania transakcji w handlu elektronicznym, zarządzania ogromnymi ilościami kluczowych informacji o klientach itd. Relacyjna baza danych może służyć do zaspokajania dowolnych potrzeb informacyjnych w sytuacjach, w których elementy danych są ze sobą powiązane i muszą być zarządzane w sposób bezpieczny, oparty na regułach i spójny.
Relacyjne bazy danych istnieją od lat 70-tych XX wieku. Zalety modelu relacyjnego sprawiają, że jest to nadal najszerzej akceptowany model baz danych.
Spójność danych
Model relacyjny najskuteczniej zachowuje spójność danych w aplikacjach i kopiach baz danych (zwanych instancjami). Na przykład, gdy klient wpłaca pieniądze w bankomacie, a następnie sprawdza saldo konta w telefonie komórkowym, oczekuje, że natychmiast zobaczy ten depozyt w zaktualizowanym saldzie konta. Relacyjne bazy danych pozwalają zapewnić taką spójność danych, sprawiając, że wiele instancji bazy danych zawiera przez cały czas te same dane.
W przypadku innych typów baz danych utrzymanie przez cały czas takiego poziomu spójności przy dużej ilości danych jest trudne. Niektóre najnowsze bazy danych, takie jak NoSQL, mogą zapewniać tylko „spójność końcową”. Zgodnie z tą zasadą, gdy baza danych jest skalowana lub gdy wielu użytkowników korzysta z tych samych danych w tym samym czasie, dane potrzebują trochę czasu, aby „dogonić” stan aktualny. Spójność końcowa jest akceptowalna w przypadku niektórych zastosowań, takich jak prowadzenie list w katalogu produktów, ale w przypadku newralgicznych operacji biznesowych, takich jak transakcje związane z obsługą koszyka zakupów, „złotym standardem” jest nadal relacyjna baza danych.
Zatwierdzanie i niepodzielność
Relacyjne bazy danych obsługują reguły i zasady biznesowe na bardzo szczegółowym poziomie — obowiązują na przykład bardzo rygorystyczne zasady zatwierdzania (tj. wprowadzania zmian w bazie danych na stałe). Rozważmy na przykład bazę danych dotyczącą stanu zapasów, która monitoruje trzy zawsze używane razem części. Kiedy jedna z tych części jest pobierana z zapasów, muszą zostać pobrane również pozostałe dwie. Jeśli jedna z tych trzech części jest niedostępna, nie może zostać pobrana żadna z nich — aby baza danych dokonała zatwierdzenia, muszą być dostępne wszystkie trzy części. Relacyjna baza danych nie zatwierdzi do wydania jednej części, o ile nie może zatwierdzić wszystkich trzech. Ta wielopłaszczyznowość zatwierdzania jest nazywana niepodzielnością. Niepodzielność jest kluczem do zachowania dokładności danych w bazie danych i zapewnienia ich zgodności z zasadami, przepisami i polityką firmy.
ACID i relacyjne bazy danych
Transakcje relacyjnej bazy danych są definiowane przez cztery właściwości: niepodzielność, spójność, izolacja i trwałość — określane zazwyczaj skrótem ACID od pierwszych liter tych słów w języku angielskim (atomicity, consistency, isolation, durability).
- Niepodzielność określa wszystkie elementy składające się na kompletną transakcję bazy danych.
- Spójność określa zasady utrzymywania elementów danych we właściwym stanie po transakcji.
- Izolacja oznacza, że efekt transakcji będzie niewidoczny dla innych, dopóki nie zostanie ona zatwierdzona, aby uniknąć nieporozumień.
- Trwałość oznacza, że zmiany w danych stają się trwałe po zatwierdzeniu transakcji.
Procedury składowane i relacyjne bazy danych
Dostęp do danych obejmuje wiele powtarzających się czynności. Na przykład proste zapytanie, które ma zapewnić uzyskanie informacji z tabeli danych, może wymagać powtórzenia setek lub tysięcy razy, aby uzyskać pożądany wynik. Te funkcje dostępu do danych wymagają jakiegoś rodzaju kodu, aby uzyskać dostęp do bazy danych. Twórcy aplikacji nie chcą pisać nowego kodu dla tych funkcji w każdej nowej aplikacji. Na szczęście relacyjne bazy danych obsługują procedury składowane będące blokami kodu, do których można uzyskać dostęp poprzez proste wywołanie aplikacji. Na przykład pojedyncza procedura składowana może zapewnić spójne znakowanie rekordów dla użytkowników wielu aplikacji. Procedury składowane mogą również pomagać programistom w zadbaniu o to, aby określone funkcje danych w aplikacji zostały zaimplementowane w konkretny sposób.
Blokowanie bazy danych i współbieżność
Kiedy wielu użytkowników lub wiele aplikacji próbuje jednocześnie zmienić te same dane, w bazie danych mogą występować konflikty. Techniki blokowania i współbieżności zmniejszają ryzyko konfliktów przy jednoczesnym zachowaniu integralności danych.
Blokowanie uniemożliwia innym użytkownikom i aplikacjom dostęp do danych podczas ich aktualizacji. W niektórych bazach danych blokowanie dotyczy całej tabeli, co ma negatywny wpływ na wydajność aplikacji. Inne bazy danych, takie jak relacyjne bazy danych Oracle, stosują blokady na poziomie rekordu, umożliwiając dostęp do pozostałych rekordów w tabeli, co pomaga zapewnić lepszą wydajność aplikacji.
Współbieżność występuje wówczas, gdy wielu użytkowników lub wiele aplikacji jednocześnie wywołuje zapytania dotyczące tej samej bazy danych. Funkcja ta zapewnia odpowiedni dostęp użytkownikom i aplikacjom, zgodnie ze zdefiniowanymi zasadami kontroli danych.
Na co zwracać uwagę przy wyborze relacyjnej bazy danych
Oprogramowanie używane do przechowywania, wyszukiwania i pobierania danych przechowywanych w relacyjnej bazie danych oraz do zarządzania nimi to tzw. system zarządzania relacyjnymi bazami danych (RDBMS). RDBMS zapewnia interfejs między użytkownikami i aplikacjami a bazą danych, a także funkcje administracyjne do zarządzania przechowywaniem danych, dostępem i wydajnością.
Na wybór określonego typu bazy danych i produktów związanych z relacyjną bazą danych wypływa kilka czynników. Wybór RDBMS zależy od potrzeb biznesowych firmy. Należy sobie wtedy zadać następujące pytania:
- Jakie są nasze wymagania w zakresie dokładności danych? Czy przechowywanie i dokładność danych zależą od logiki biznesowej? Czy nasze dane są objęte rygorystycznymi wymaganiami dotyczącymi dokładności (na przykład dane finansowe i raporty dla organów administracji publicznej)?
- Czy potrzebujemy skalowalności? Jaka jest skala zarządzanych danych i jaki jest oczekiwany wzrost ich ilości? Czy model bazy danych będzie musiał obsługiwać lustrzane kopie bazy danych (jako osobne instancje) w celu skalowania? Jeśli tak, czy może utrzymać spójność danych w tych instancjach?
- Jak ważna jest współbieżność? Czy wielu użytkowników i wiele aplikacji będzie potrzebować jednoczesnego dostępu do danych? Czy oprogramowanie bazy danych obsługuje współbieżność, jednocześnie chroniąc dane?
- Jakie są nasze potrzeby w zakresie wydajności i niezawodności? Czy potrzebujemy produktu o wysokiej wydajności i niezawodności? Jakie są wymagania dotyczące wydajności odpowiedzi na zapytania? Jakie są zobowiązania dostawcy dotyczące umów o poziom usług (SLA) lub nieplanowanych przestojów?
Relacyjna baza danych przyszłości: autonomiczna baza danych
Z biegiem lat relacyjne bazy danych stały się lepsze, szybsze, wydajniejsze i łatwiejsze w obsłudze. Ale są także bardziej skomplikowane, a administrowanie bazą danych od dawna jest zajęciem pełnoetatowym. Zamiast wykorzystywać swoją wiedzę i koncentrować się na opracowywaniu innowacyjnych aplikacji przynoszących firmie korzyści, programiści muszą spędzać większość czasu na działaniach związanych z zarządzaniem, niezbędnych do zapewnienia optymalnego działania bazy danych.
Oferowana obecnie technologia autonomiczna opiera się na mocnych stronach modelu relacyjnego, udostępniając nowy typ relacyjnej bazy danych. Samoczynna baza danych (zwana również autonomiczną bazą danych ) zachowuje moc obliczeniową i zalety modelu relacyjnego, ale wykorzystuje sztuczną inteligencję (AI), samouczenie się maszyn i automatyzację do monitorowania obsługi zapytań i zadań zarządzania oraz zwiększania jej wydajności. Na przykład, aby poprawić wydajność obsługi zapytań, samoczynna baza danych może postawić hipotezę i przetestować indeksy w celu przyspieszenia obsługi zapytań, a następnie przekazać najlepsze wyniki do produkcji — wszystko samodzielnie. Samoczynna baza danych wprowadza tego rodzaju usprawnienia nieustannie, nie angażując przy tym człowieka.
Technologia autonomiczna zwalnia programistów z wykonywania przyziemnych zadań związanych z zarządzaniem bazą danych. Nie muszą oni na przykład z wyprzedzeniem definiować wymagań dotyczących infrastruktury. Zamiast tego, dzięki samoczynnej bazie danych, mogą swobodnie dodawać zasoby pamięci masowej i moc obliczeniową w miarę rozrastania się bazy danych. Programiści mogą łatwo, w zaledwie kilku krokach, utworzyć autonomiczną relacyjną bazę danych.
* materiał powyższy zaczerpnięty ze strony Oracle.com
Relacje
Bazy relacyjne używają powiązań między rekordami tzw. relacji, jest to matematyczna reprezentacja rekordów, gdzie jej zaletami są:
- czytelność od strony formalnej,
- zdolność do wykorzystania sformalizowanych języków zapytań,
- łatwość zrozumienia właściwości relacji.
Relacje są wiązaniami pomiędzy wierszami Tabel (krotkami), taka notacja w tabelach ma charakterystyczne dla niej cechy, a mianowicie:
- wizualnie prosta do zrozumienia,
- przejrzysta struktura danych,
- jest gotowa do współpracy z językami sformalizowanymi (ścisła notacja wewnątrz tablicy),
- jest adekwatna do większości zastosowań.
Słowniczek kontekstowy
- Schemat bazy danych jest zbiorem 1 lub więcej schematów relacji,
- Relacja jest przedstawiona w postaci dwuwymiarowej tabeli,
- Kolumny tabeli to atrybuty relacji,
- Wiersze tabeli to krotki relacji,
- Każda krotka to instancja (wystąpienie) relacji,
- Składowa krotki to wartość atrybutu w krotce,
- Liczebność tabeli to liczba krotek (wierszy tabeli),
- Stopień tabeli to ilość atrybutów (kolumn tabeli).
Tworzenie relacji (tabeli)
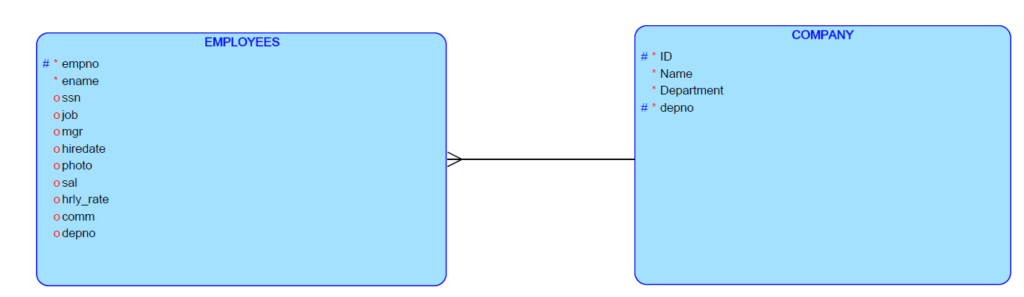
Tablica: hr.admin zawierająca dane o pracownikach w dziale Human Resources hipotetycznej firmy może wymagać atrybutów tak jak poniżej:
- empno – numer pracownika,
- ename – jego nazwa,
- ssn – hasło dostępowe,
- job – przydział obowiązków zawodowych (stanowisko),
- mgr – grupa zaszeregowania,
- hiredate – data zatrudnienia,
- photo – zdjęcie pracownika,
- sal – wynagrodzenie,
- hrly_rate – staż pracy,
- comm –
- deptno – numer departamentu (działu).
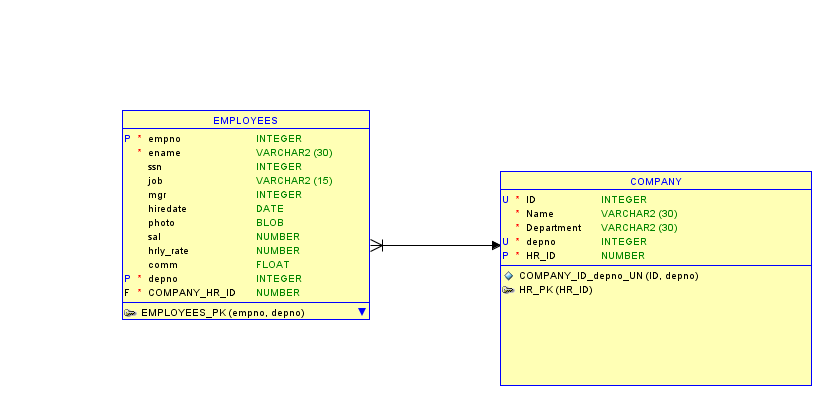
w zapisie w SQL Oracle przybiera poniższą postać:
CREATE TABLE hr.admin_emp (
empno NUMBER(5) PRIMARY KEY,
ename VARCHAR2(15) NOT NULL,
ssn NUMBER(9) ENCRYPT,
job VARCHAR2(10),
mgr NUMBER(5),
hiredate DATE DEFAULT (sysdate),
photo BLOB,
sal NUMBER(7,2),
hrly_rate NUMBER(7,2) GENERATED ALWAYS AS (sal/2080),
comm NUMBER(7,2),
deptno NUMBER(3) NOT NULL
CONSTRAINT admin_dept_fkey REFERENCES
hr.departments (department_id))
TABLESPACE admin_tbs
STORAGE ( INITIAL 50K);
Powyżej zaprezentowana została struktura zapytania DDL tworzenia tabeli określającej relację. Poniżej odwzorowana w postaci tabeli z wartościami (składowymi krotek).
| empno | ename | ssn | job | mgr | hiredate | photo | sal | hrly_rate | comm | deptno |
| 1 | JKowalski | 6bc1bee22 | sprzedawca | 2012-03-01 | xxx | 2 356,00 | 1,13 | 1019 | ||
| 2 | MKabierz | a63f362q8 | serwisant | 2020-12-01 | xxx | 2 299,00 | 1,11 | 997 | ||
| 3 | ZFrans | 66h3why36 | zarząd | 2002-01-01 | xxx | 7 890,00 | 3,79 | 1321 | ||
| 4 | APotracka | 3tey3u22u | serwisant | 2018-09-01 | xxx | 2 299,00 | 1,11 | 2320 | ||
| 5 | GJózefowicz | hh3wi2291 | sprzedawca | 2020-02-15 | xxx | 2 356,00 | 1,13 | 234 |
W ramach powyższej konstrukcji możemy wyróżnić charakterystyczne jej elementy, a mianowicie:
Klucz główny relacji PK (Primary Key) którym jest taki zbiór atrybutów relacji, gdzie zachodzi zasada, że każdy element zbioru jest unikalny, przez co możliwe jest zidentyfikowanie każdej krotki w relacji poprzez ten klucz. Klucz taki musi występować w krotce i nie może być pominięty (Not Null). Klucz taki wybierany jest ze zbioru kluczy kandydujących.
Klucz kandydujący to każdy zbiór atrybutów relacji w których zachodzi zasada unikalności (niepowtarzalności) wartości. W relacji może ich występować wiele.
Klucz prosty to taki klucz który jest zbiorem jednoelementowym.
Klucz złożony to taki klucz którego zbiór atrybutów jest wieloelementowy.
Klucz obcy FK (Foreign Key) to zbiór atrybutów relacji pochodzących z tej samej dziedziny co klucz główny relacji powiązanej z nią w bazie danych. Służy do reprezentacji powiązań między danymi.
Operacje DML, DDL, DCL, DQL
Operacje DML, DDL, DCL występują w każdym języku SQL. Jest to podział operacji wykonywanych na bazie lub serwerze w zależności od grupy czynności, jaką wykonujesz: manipulacja danymi, definiowanie, sterowanie (nie mylmy z kontrolą), wyświetlanie tabeli / setu danych.
DQL – Data Query Language. DQL to instrukcje, za pomocą których możesz otrzymać z bazy określone dane. Najważniejszym poleceniem jest tutaj SELECT.
DML – Data Manipulation Language. Instrukcje manipulacji danymi. Możemy do nich zaliczyć polecenia takie jak INSERT, UPDATE, DELETE. Najważniejszą cechą tych instrukcji jest to, że za ich pomocą możemy manipulować danymi w obiektach takich jak tabele.
DDL – Data Definition Language. Instrukcje definiujące. Możemy do nich zaliczyć polecenia takie jak CREATE, ALTER, DROP. Za pomocą instrukcji DDL nie manipulujemy bezpośrednio danymi, a ich strukturą. Możemy zdefiniować kolumny tabel, zmienić typy danych, czy usunąć obiekt taki jak widok, czy tabela.
DCL – Data Control Language. Instrukcje sterujące uprawnieniami w bazie danych / serwerze. Za ich pomocą możemy dandawać np uprawnienia użytkownikom do obiektów, przypisywać role, zmieniać hasła itp. Najważniejsze grupy poleceń to GRANT, DENY, REVOKE. Za pomocą GRANT przyznajemy uprawnienia. REVOKE służy do odbierania uprawnień. DENY zabrania dostępu. Instrukcje te są szczególnie istotne przy administracji serwerem.
Zadanie
Zadanie 1 do samodzielnej pracy laboratoryjnej: Rozważ temat bazy danych dotyczący obsługi centrum logistycznego – zaproponuj relacje z atrybutami i określ ich definicje – przedstaw je w 3NF z zaznaczeniem kluczy podstawowych (primary key) i pośrednich (foreign key). Bazę wykreuj w Data Modelerze w wersji logicznej i relacyjnej. Spróbuj zapisać bazę w notacji SQL, a następnie wygeneruj (eksport) z Data Modelera i porównaj notacje (kolumna obok kolumny) zaproponowane przez Ciebie i program – opisz różnice i zamieść swoje uwagi.
Zadanie 2 do samodzielnej pracy laboratoryjnej: Poniżej zostały przedstawione zakwizytowane dane o różnej charakterystyce: Dane do pobrania do zadania. (wspomóż się informacjami w dołączonym pliku). Dokonaj ich przeglądu, a następnie zaproponuj strukturę bazy danych z dekompozycją do 3NF, określ klucze i wskaż powiązania relacyjne. Samą strukturę (bez danych) zapisz jako odpowiedź i prześlij w .pdf.