Oracle SQL – czy to “inny” SQL?!
SQL w wydaniu firmy Oracle nie różni się od innych silników opartych na Structured Query Language w ogólnym podejściu, jest jednak wiele drobnych różnic powodujących, że kod napisany dla MySQL czy MariaDB może nie być możliwy wprost do przeniesienia na platformę Oracle czy MS.
Ogólne zasady są takie same. Główne nazewnictwo w ramach grup rozkazowych DQL1Data Query Language np. SELECT, DML2Data Modification Language np. DELETE, UPDATE, czy INSERT, DDL3Data Definition Language np. CREATE, DROP, ALTER, czy DCL4Data Control Language np. GRANT, REVOKE, DENY jest identyczne. Różnice dotyczą specyficznej konfiguracji tych rozkazów dla dla specyfiki systemu w którym uruchamiane są skrypty SQL.
SQL Developer – środowisko pracy
W przypadku Oracle SQL możemy skorzystać ze środowiska pracy Oracle SQL Developer łączącego z serwerowym silnikiem bazodanowym. Oprogramowanie jest do pobrania ze strony Oracle. W ramach zapoznawania się z notacją SQL charakterystyczną dla Oracle może być pomocny dostęp do dokumentacji języka, jaki znajduje się w sekcji DOCS na serwerze Oracle.
Po pobraniu oprogramowania Oracle SQL Developer, które zazwyczaj jest dostępne w postaci paczki .zip, należy je wyodrębnić do niezależnego katalogu w postaci nieskompresowanej. Oprogramowanie to, podobnie do poznanego wcześniej Data Modelera jest napisane w języku Java, a dostarczane użytkownikom nie wymaga odrębnej instalacji. W wyodrębnionym katalogu znajduje się uruchomieniowy plik sqldeveloper.exe, stanowiący trzon oprogramowania.
Plik ten jest wejściem do uruchomienia programu.
Konfiguracja SQL Developera
Po uruchomieniu oprogramowania należy skonfigurować je do pracy ze wskazanym serwerem bazodanowym w ramach którego tworzone i przetwarzane będą bazy danych.
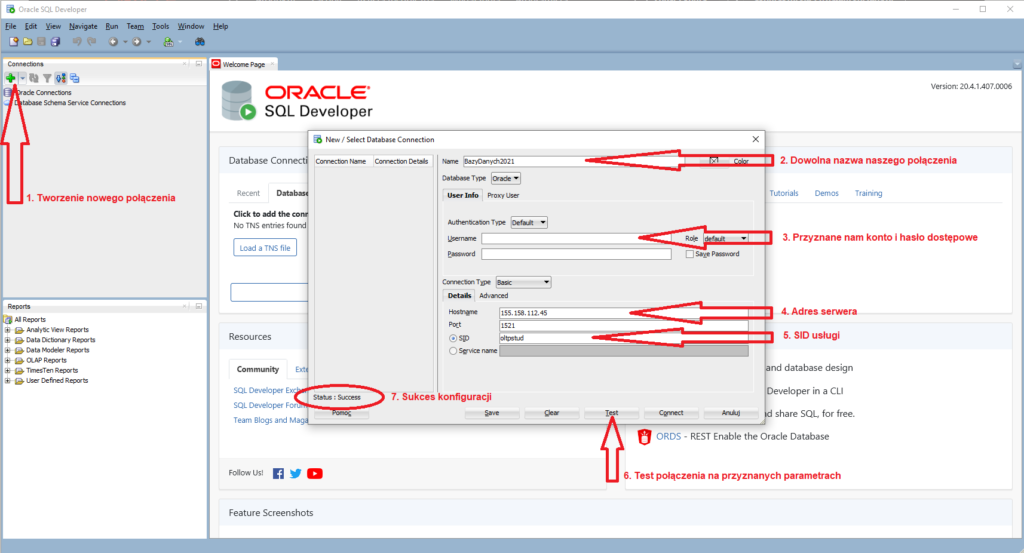
W ramach indywidualnej personalizacji należy wpisać login i hasło (krok 3), można też zaznaczyć opcję Save Password, by nie musieć powtarzać hasła za każdym logowaniem do serwera.
Należy teraz zapisać konfigurację połączenia (Save) i ewentualnie rozpocząć to połączenie (Connect).
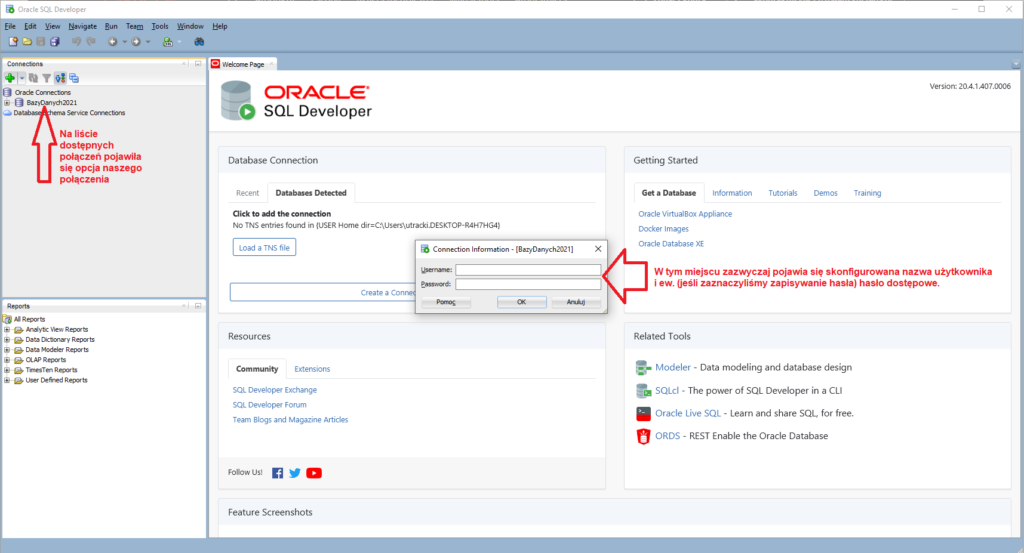
Po udanym połączeniu otrzymujemy środowisko gotowe do współpracy z serwerem SQL.
Problemy z uruchomieniem SQL Developera
Czasem okazać się może, że SQL Developer nie uruchomi się. Pojawi się początkowy ekran z paskiem postępu, który zatrzyma się w okolicach takich jak oznaczone na zdjęciu poniżej.

Po chwili widziany ekran startowy aplikacji znika i… nic się nie dzieje. Zaglądając nieco głębiej w logi uruchamiania możemy zaobserwować następujące komunikaty.
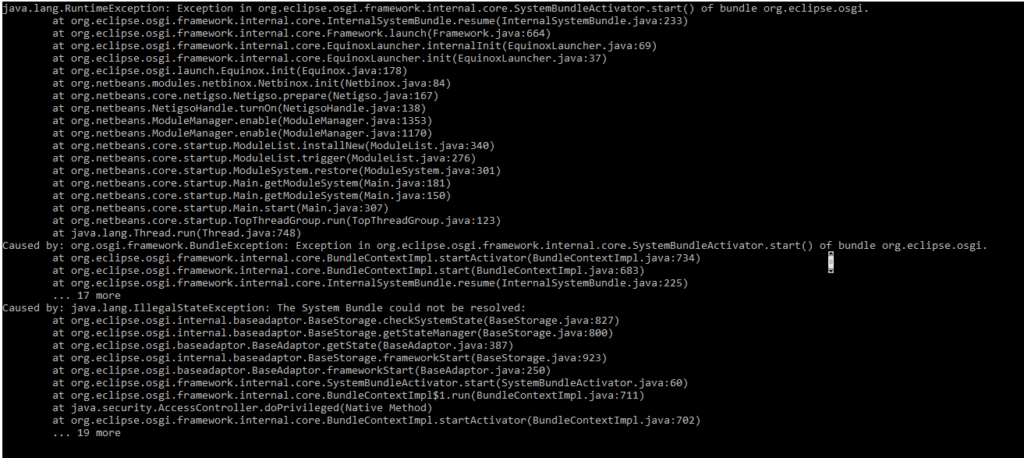
Wymieniony wyżej problem może dotyczyć braku niezbędnej biblioteki Java SE Development KIT (JDK) którą to trzeba ściągnąć z serwerów Oracle i zainstalować. W tym akurat przypadku problemem jest umieszczenie katalogu z którego uruchamiamy aplikację. Nie należy rozpakowanego katalogu umieszczać w zbyt zagnieżdżonych lokacjach, ponieważ nie radzi sobie zbyt dobrze z dostępem do niezbędnych bibliotek. Najlepiej umieścić go w głównym katalogu wybranej partycji. Po wykonaniu tej czynności aplikacja powinna się już bez problemu uruchamiać.
SQL – składnia języka
1. Tworzenie tablic
Tablice są podstawową jednostką przechowywania danych w bazie danych. Dane przechowywane są w postaci krotek w nazwanych kolumnach. Definiując tablicę określamy jej nazwę np. WYDZIALY oraz zbiór kolumn określających atrybuty jakich wartości chcemy przechowywać w tablicy. Nadajemy każdej kolumnie jej nazwę np. IDwydzialu, Nazwa itp oraz określamy typ wartości tych atrybutów np. VARCHAR2, DATE, czy NUMBER wraz z określeniem wymaganej szerokości typu (np. ilość miejsc w nazwie). Zakres może być predeterminowany poprzez sam rodzaj typu tak jak np. DATA. Jeśli typem jest NUMBER, to definiujemy precyzję i zakres zamiast ilości znaków dla danej. Wiersz stworzony z tak zdefiniowanych typów tworzy nam rekord (krotkę) danych.
Możesz zdefiniować zasady dla każdej kolumny tablicy. Zasady te nazywają się warunkami integralności. Takim przykładem może być reguła NOT NULL, która wymusza, aby w kolumnie oznaczonej tą regułą wszystkie rekordy zawierały wartości na pozycji tego pola.
Dla przykładu:
create table DEPARTMENTS ( deptno number, name varchar2(50) not null, location varchar2(50), constraint pk_departments primary key (deptno) );
Tablice mogą się wzajemnie wiązać poprzez wskazanie relacji za pomocą wskazania atrybutu i zadeklarowania go w tablicy jako klucza obcego istniejącego jako klucz podstawowy w innej tablicy. Wymaga to zachowania integralności relacji.
Dla przykładu:
create table EMPLOYEES ( empno number, name varchar2(50) not null, job varchar2(50),manager number, hiredate date, salary number(7,2), commission number(7,2), deptno number, constraint pk_employees primary key (empno), constraint fk_employees_deptno foreign key (deptno) references DEPARTMENTS (deptno));
Klucze obce muszą mieć referencję do Kluczy Podstawowych (głównych) istniejących w innej tablicy. Stąd aby powiązać jedną tablicę wskazując w jej definicji klucz obcy (Foreign Hey), wpierw musi istnieć tablica w której dany atrybut jest oznaczony jako podstawowy (Primary Key).
2. Tworzenie przełączników
Przełączniki są procedurami zapisanymi w bazie danych i są uruchamiane w sytuacji wyzwalanej wskazanym zdarzeniem. Tradycjonalnie, przełączniki wspomagały egzekucję kodu proceduralnego, który to w przypadku Oracle jest zwany blokiem PL/SQL. PL to właśnie Procedural Language. Tak jak INSERT, UPDATE, czy DELETE dotyczą tablic lub widoków, tak przełączniki wspierają system i zdarzenia w zakresie bazy danych czy schematów.
Przełączniki są zazwyczaj używane do automatycznego zapełnienia tablicy kluczy głównych (Primary Keys) tak jak na przedstawionym poniżej przykładzie. Używamy ich aby uzyskać unikalne identyfikatory (GUID) w skali globalnej.
create or replace trigger DEPARTMENTS_BIU before insert or update on DEPARTMENTS for each row begin if inserting and :new.deptno is null then :new.deptno := to_number(sys_guid(), 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'); end if; end; / create or replace trigger EMPLOYEES_BIU before insert or update on EMPLOYEES for each row begin if inserting and :new.empno is null then :new.empno := to_number(sys_guid(), 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'); end if; end; /
3. Dodawanie danych do tabeli
W sytuacji, gdy mamy już zdefiniowaną strukturę tablicy (i ustawione przełączniki) możemy dodać dane do tablicy używając polecenia INSERT. Z uwagi na przykład wcześniejszy, gdzie ustawiliśmy Now that we have tables created, and we have triggers to automatically populate our primary keys, we can add data to our tables. Z uwagi na fakt, iż w naszym przykładzie mieliśmy ustawioną relację zależności od tablicy DEPARTMENTS w której wartości jednego z atrybutów są użyte jako źródłowe, a tablica EMPLOYEES korzysta z nich jako foreign key INSERT wpierw wprowadzimy dane do tablicy DEPARTMENTS.
insert into departments (name, location) values ('Finance','New York');
insert into departments (name, location) values ('Development','San Jose');
Sprawdźmy teraz, czy wprowadzenie danych się udało:
select * from departments;
Można zauważyć, że wartości kolumny ID zostały automatycznie wygenerowane. Terazm możemy dodać kilka danych do tablicy EMPLOYEES, ale na polach, które wskazaliśmy jako foreign key musimy umieścić odpowiednie, wygenerowane w poprzedniej operacji dane DEPTID. Poniższy przykład pokazuje jak możemy użyć to w nieco bardziej zaawansowany sposób niż ręczne przepisywanie tych wartości z drugiej tabeli.
insert into EMPLOYEES (name, job, salary, deptno) values ('Sam Smith','Programmer',5000,(select deptno from departments where name = 'Development'));
insert into EMPLOYEES (name, job, salary, deptno) values ('Mara Martin','Analyst',6000, (select deptno from departments where name = 'Finance'));
insert into EMPLOYEES (name, job, salary, deptno) values ('Yun Yates','Analyst', 5500, (select deptno from departments where name = 'Development'));
4. Indeksowanie Kolumn
Zazwyczaj deweloperzy stosują indeksowanie z trzech podstawowych powodów:
- aby powiązać wartości unikalne z kolumną,
- aby zwiększyć wydajność przetwarzania zapytań,
- aby zapobiec propagacji ewentualnej blokady rekordów czy tablic korzystających z deklaratywnej integralności referencyjnej w trakcie przeprowadzania aktualizacji.
Kiedy tablica jest utworzona a Primary Key wskazany, to indeks jest automatycznie tworzony dla zapewnienia spójności i unikalności zgodnie z warunkiem istnienia PK. Jeśli jakąś kolumnę oznaczysz jako UNIQUE to takie indeksowanie dla tej kolumny będzie także przeprowadzone. Aby zobaczyć jakie indeksy zostały utworzone dla konkretnej tablicy należy użyć poniższego przykładu zapytania.
select table_name "Table", index_name "Index", column_name "Column", column_position "Position" from user_ind_columns where table_name = 'EMPLOYEES' or table_name = 'DEPARTMENTS' order by table_name, column_name, column_position
Jest to dobra strategia by indeksować w tabeli te kolumny, które stanowią klucze obce tworząc relacje z innymi tablicami. W naszym przykładzie w tabeli EMPLOYEE i DEPARTMENTS kolumna DEPTNO stanowiła wzajemne powiązanie w jednej będąc PK a w drugiej jako FK.
create index employee_dept_no_fk_idx on employees (deptno)
Możemy także założyć, czy tablica EMPLOYEE nie będzie regularnie przeszukiwana po wartościach kolumny NAME. W takim przypadku jest dobrą praktyką, aby ta kolumna również była indeksowana aby przyśpieszyć wyszukiwanie. Można to uczynić tak jak na poniższym przykładzie.
create unique index employee_ename_idx on employees (name)
Oracle zapewnia wiele różnych metod indeksowania dla pól innych rodzajów jak np. obrazy. Jest to jednak temat wykraczający poza ramy tego podstawowego opracowania.
5. Odpytywanie Bazy Danych
Do wyselekcjonowania danych z pojedynczej tablicy po prostu użyj polecenia SELECT … FROM … WHERE … ORDER BY … .
select * from employees;
Dla odpytania dwu powiązanych tablic możesz użyć funkcjonalności join.
select e.name employee,
d.name department,
e.job,
d.location
from departments d, employees e
where d.deptno = e.deptno(+)
order by e.name;
Jako alternatywa dla join można użyć wewnętrznego () select dla zapytania SQL.
select e.name employee,
(select name
from departments d
where d.deptno = e.deptno) department,
e.job
from employees e
order by e.name;
6. Dodawanie Kolumn
W momencie, gdy masz już zdefiniowaną i stworzoną tablicę nadal możesz do niej dodać nową kolumnę używając polecenia ALTER TABLE … ADD …
Dla przykładu:
alter table EMPLOYEES
add country_code varchar2(2);
7. Odpytywanie Oracle Data Dictionary
Dane z MetaTablic są dostępne poprzez odpytanie Oracle Data Dictionary. Poniżej widoczny jest przykład jak to zrobić.
select table_name, tablespace_name, status
from user_tables
where table_Name = ‘EMPLOYEES’;
select column_id, column_name , data_type
from user_tab_columns
where table_Name = ‘EMPLOYEES’
order by column_id;
8. Aktualizacja Danych
Zawsze istnieje możliwość aktualizacji danych zawartych w tablicach. Dokonujemy tego używając polecenia UPDATE.
update employees set country_code = ‘PL’;
Powyższe polecenie zaktualizuje wszystkie wiersze tablicy ustawiając country_code = PL. Można jednakże również wskazać warunkiem o jakie wiersze może nam chodzić.
update employees set commission = 2000 where name = ‘Sam Smith’;
Teraz spróbujmy odpytać naszą bazę by zobaczyć jaki odniosło to skutek.
select name, country_code, salary, commission from employees order by name;
9. Agregowanie Zapytań
Możesz zagregować zapytania za pomocą funkcji agregujących. Należy także użyć odpowiedniej funkcji NVL aby zachować poprawność agregowania wartości typu null.
select
count(*) employee_count,
sum(salary) total_salary,
sum(commission) total_commission,
min(salary + nvl(commission,0)) min_compensation,
max(salary + nvl(commission,0)) max_compensation
from employees;
10. Kompresowanie Danych
Baza danych może się rozrastać w “nieskończoność”, aby temu przeciwdziałać możesz rozważyć włączenie kompresji danych. Taka operacja zmniejsza użycie przestrzeni dyskowej oraz pamięci operacyjnej. Kompresja może też przyśpieszyć zapytania odczytu danych. Co prawda wymaga wtedy większego użycia mocy procesora dla dekompresji i DML, ale jest to często w rezultacie bardziej optymalne. Kompresja tabeli jest całkowicie transparentna dla aplikacji. Szczególnie pozytywnie wpływa na on-line’owe procesy analityki (OLAP) z uwagi na przepustowość sieci i minimalizację wielkości danych przesyłanych, ale także może mieć korzystny wpływ na systemy online’owych procesów transakcyjnych (OLTP).
Aby właczyć kompresję wystarczy użyć polecenia COMPRESS w trakcie tworzenia tablicy przez CREATE TABLE. Można także modyfikować już istniejącą strukturę dzięki poleceniu ALTER TABLE. W tym drugim jednakże przypadku dane już istniejące w bazie NIE ZOSTANĄ skompresowane, a kompresja dotyczyć będzie jedynie nowo dodawanych danych. Analogicznie za pomocą polecenia ALTER TABLE…NOCOMPRESS można wyłączyć stosowanie kompresji, co jednak pozostanie bez wpływu na już umieszczone dane w tablicy – te pozostaną takie jaki był status kompresji w momencie ich dodawania do tablicy.
Aby uruchomić kompresję danych w tablicach należy użyć poniższej konstrukcji polecenia.
alter table EMPLOYEES compress for oltp;
alter table DEPARTMENTS compress for oltp;
11. Kasowanie Danych
Możesz użyć komendy DELETE do skasowania danych z tabeli. Dla przykładu aby skasować wskazany rekord:
delete from employees
where name = ‘Sam Smith’;
12. Usuwanie Tablic
Możesz usunąć tablicę ze struktury Twojej bazy za pomocą komendy DROP. Ta czynność usunie wszystkie rekordy zgromadzone w tablicy wraz z ewentualnie istniejącymi tablicami pomocniczymi zawierającymi indeksy i przełączniki utworzone dla tej tablicy. Przykładowo podane niżej formuły komendy DROP usuną tablice departments i employees z bazy danych, dodatkowo opcjonalnie umieszczone modyfikatory cascade constraints wyłączą zasady usuwania pozwalając na usunięcie danych w dowolnie sekwencyjny sposób.
drop table departments cascade constraints;
drop table employees cascade constraints;
13. Przywracanie Usuniętych Tablic
Jeśli parametr konfiguracyjny bazy danych RECYCLEBIN jest ustawiony na WŁĄCZONY (ON) to usunięcie tablicy (DROP) umieszcza ją w koszu. Aby sprawdzić, czy jest możliwe jej przywrócenie należy użyć następującej sekwencji:
select object_name,
original_name,
type,
can_undrop,
can_purge
from recyclebin;
Aby przywrócić taką tablicę należy użyć komendy flashback command, tak jak poniżej:
flashback table DEPARTMENTS to before drop;
flashback table EMPLOYEES to before drop;
select count() departments from departments; select count() employees
from employees;
Pierwszy skrypt
Tu znajduje się miejsce na to, abyś spróbował stworzyć swój pierwszy skrypt tworzący tablicę w ramach przydzielonego Ci miejsca w Twojej bazie danych.